Паттерн наблюдатель (Observer)
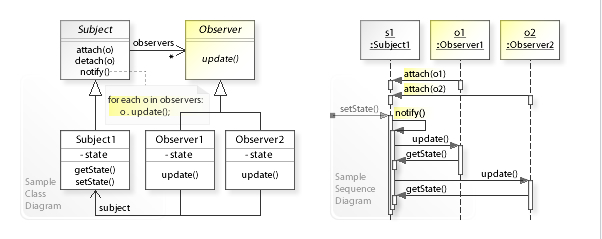
Паттерн наблюдатель (Observer) - это паттерн проектирования программного обеспечения, в котором объект, называемый субъектом, ведет список своих зависимых, называемых наблюдателями, и автоматически уведомляет их о любых изменениях состояния, обычно вызывая один из их методов. Он в основном используется для реализации распределенных систем обработки событий в программном обеспечении, "управляемом событиями" (event driven). В этих системах субъект обычно называется "потоком событий" или "источником событий", в то время как наблюдатели называются "приемниками событий". Номенклатура потока имитирует или адаптируется к физической установке, где наблюдатели физически разделены и не контролируют испускаемые события субъекта/источника потока. Этот паттерн идеально подходит для любого процесса, где данные поступают через ввод/вывод, то есть когда данные недоступны ЦПУ при запуске, но могут поступать "случайно" (HTTP-запросы, данные GPIO, ввод ...

